
Dados médicos podem salvar vidas, mas como fica sua privacidade?
Por: Monica Matsumoto com colaboração de Shridhar Jayanthi
Em tempos de big data, inteligência artificial e internet 5G, a área de processamento de dados em saúde promete grandes impactos. Há novas possibilidades de aplicações disruptivas e descobertas científicas. Entretanto, uma questão central que surge é como será feito o controle de acesso aos dados? Existem riscos envolvidos, afina seus dados de saúde são um dos dados mais íntimos que você tem! Regulações sobre a proteção à privacidade e acesso a dados privados num mundo com internet é um território complexo e com consequências ainda desconhecidas. Decisões tomadas a partir de evidências obtidas a partir de dados dessa natureza podem afetar a vida de muitas pessoas, possivelmente de uma forma injusta ou enviesada. O tema tem chamado muitas discussões.

Fonte: KHN.org.
Nessas últimas duas semanas, duas conferências em Boston (EUA) trouxeram algumas destas questões. Em Harvard, o seminário: Exagero ou Realidade – o papel de IA na saúde mundial (Hype or Reality – The role of Artificial Intelligence in global health), no MIT, um painel sobre os caminhos éticos da IA, e na Escola de Medicina da NY o evento "Saúde na era de Big Data: oportunidades e desafios" (Healthcare in the era of Big Data: Opportunities and Challenges), abordaram temas como qualidade de dados; recrutamento e consentimento; proteção de privacidade e propriedade de dados; responsabilidade corporativa e compliance, e outros temas nesta nova era da medicina e pesquisa.
(*No podcast da Academia de Ciências de NY, você pode escutar mais sobre essa discussão que ocorreu na NYU. O evento de Harvard pode ser visto nesse vídeo.)
Dados diretos e indiretos sobre a sua saúde
Para ter ideia da quantidade de informação disponível sobre sua saúde, podemos pensar em dados diretos e indiretos.
Dados diretos contemplam seus dados clínicos, guardados no seu prontuário eletrônico. São dados que registram exames laboratoriais, imagens, anamnese, valores de pressão, peso, e frequência cardíaca, relatos clínicos, medicações e diagnósticos. A cada visita é adicionado um novo conjunto destes dados. Além disso, os wearables (equipamentos portáteis continuamente utilizados por uma pessoa) têm providenciado dados diretos da saúde em quantidades nunca antes imaginadas. Por exemplos, alguns wearables monitoram o eletrocardiograma do paciente, sensores de condutividade da pele, de taxa de glicose, ou temperatura por várias horas. A quantidade de dados pode ser tão grande, que lidar com esse volume de informação quase em tempo real é novidade para os médicos, e há até questões sobre métodos e a precisão – o caso do smartwatch da Apple que promete detectar fibrilação atrial poderia levar a atendimentos desnecessários! O fato é que nunca se teve tanto acesso a amostras digitais dos pacientes, e muitas empresas estão explorando a inteligência destes dados: seu poder preditivo e de diagnóstico de doenças.
Dados indiretos, por sua vez, podem vir de origens diferentes. Alguns exemplos são as redes sociais, fotos, dados geoespaciais e até nossa voz. A nossa pegada digital, também chamada de fenótipo digital, pode servir para monitorar o nosso comportamento, cognição e estado emocional. Os hábitos digitais mostram como utilizamos a internet diariamente, como nos comunicarmos e nos relacionamos em redes sociais. Outras manifestações como a velocidade de escrita, buscas na internet e posts de selfies também trazem informações. Sistemas de GPS nos nossos celulares são capazes de registrar os lugares que visitamos – é possível por exemplo saber quantas vezes por semana você toma um chopinho no bar do lado do trabalho. Até nossa voz pode ser usada para avaliar a saúde física e mental, observando por exemplo a velocidade de fala e o tom de voz! Assistentes de voz como a Alexa (Amazon) e Siri (Google) potencialmente podem responder perguntas de saúde, ou a análise da mudança de voz pode estimar o estado do cliente.
O que pode dar errado
Uma questão crucial é quem tem acesso aos dados, e para que ele é usado. Nos EUA, existem diretrizes claras para o uso de dados e proteção de privacidade do paciente (HIPAA), mais estritamente para os dados clínicos. Mesmo assim, esses arquivos podem ser usados para pesquisa clínica ou para auditoria do plano de saúde.
Outros acordos de proteção à privacidade são muito mais frouxos, como os dados em redes sociais, sites e serviços. Sob o pretexto de melhorar a sua experiência, muitas informações são vendidas. E, apesar de existir uma intenção de anonimização de dados, sabe-se que os padrões são quase que individuais e é possível triangular dados, ou eles são até explícitos ao compartilhar sua informação.
Considerando que os dados clínicos são apenas uma pequena fração dos dados que podem indicar sua saúde, muito está descoberto de proteção. É o que Cohen e Pearlman discutem no artigo de revisão sobre privacidade de dados, na Nature Medicine. A ponta do iceberg está coberta por políticas de proteção, enquanto o restante fica obscuro.
Inferência e big data
Um conceito interessante é que inferências trazidas por predição de dados, tem bases legais para não serem consideradas quebra de privacidade. Um exemplo que os autores usam é a observação de uma pessoa que observa mudanças na dieta de uma amiga. Uma pessoa que nota que sua amiga parou de ingerir bebidas alcóolicas e que ganhou algum peso pode concluir que ela está grávida, e esse tipo de inferência não caracteriza violação de privacidade. O que seria diferente se o amigo invadisse o consultório médico atrás de arquivos, ou entrasse no email dela atrás de informação, uma clara quebra de privacidade. As inferências de big data estariam mais próximas do primeiro caso, sob esse conceito.
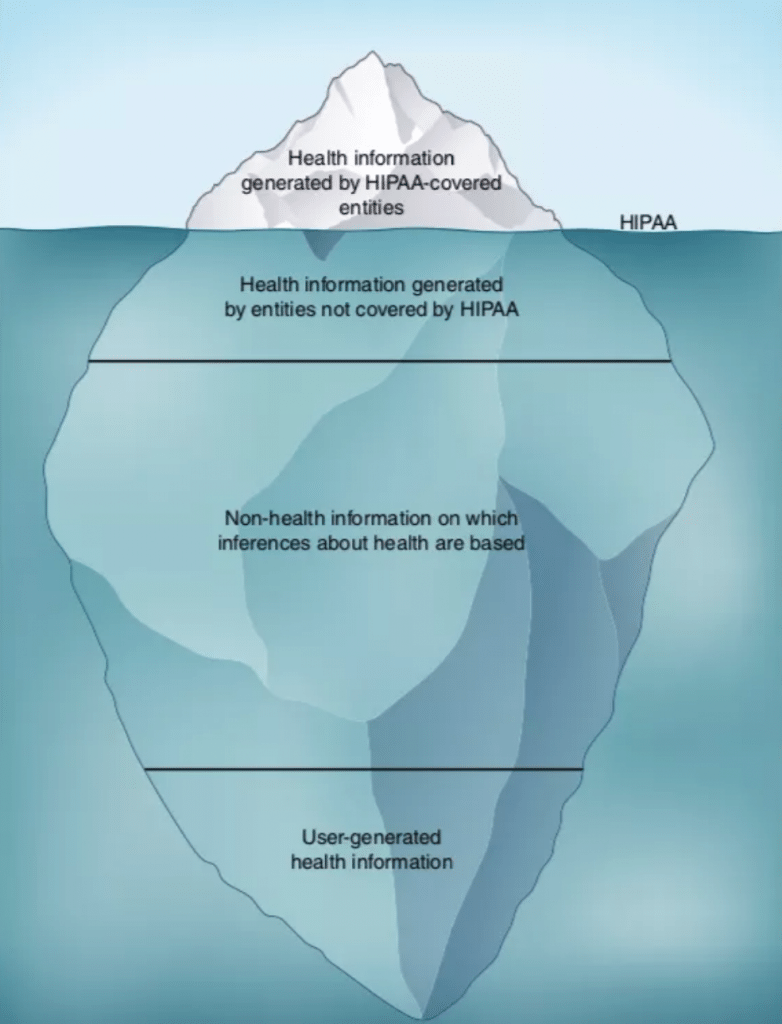
Fonte: Nature Medicine.
Discriminação e compartilhamento de dados pessoais
Quando as informações sobre sua saúde estão tão expostas, e na realidade não se sabe quem tem acesso a elas, pessoas podem tornar-se vulneráveis à discriminação sem nem saber. Por exemplo uma pessoa pode ter uma oferta de emprego recusada ou acesso a determinados tratamentos negados por conta disso, o que pode acarretar consequências financeiras ou constrangimentos. Um precedente foi o imenso preconceito que gays sofreram durante a epidemia de HIV nos anos 80. Um outro risco é o de usos secundários dessa informação facilitar ataques à credibilidade de um indivíduo por conta de uma doença ou de uma informação revelada através de seu material genético. Não é difícil imaginar um mundo onde imobiliárias neguem conceder casas para pessoas com algum tipo de doença contagiosa, um uber que se recuse a transportar mulheres grávidas, ou uma empresa se negando a contratar pessoas com propensão puramente genética a distúrbios mentais. Essas decisões podem ser economicamente racionais mas são potencialmente injustas e desumanas.
O que pode dar certo para a saúde
O potencial de impacto positivo na saúde individual e coletiva é enorme. Para a saúde pública, o uso de dados abundantes pode por exemplo apontar um surto de gripe antes de qualquer sistema de vigilância sanitária. Outra aplicação seria viabilizar ensaios clínicos em larguíssima escala, dado que os estudos atualmente feitos tendem a ser limitados e incapazes de representar toda a diversidade da população de pacientes. Novos dados podem abraçar a complexidade de tratamentos e respostas dos pacientes, e trazer evidências de forma mais rápida. Na esfera do pessoal, a trituração de dados por IA pode trazer tratamentos personalizados e mais eficientes e facilitar monitoração constante de sinais que podem impactar a saúde física e mental!
Políticas de privacidade e nossa saúde
Muitas vezes os principais atores do ambiente clínico, o médico e o paciente, não tem ideia dos possíveis desdobramentos do vasto arquivo digital gerado. Uma vez que o médico aperta enter ou o paciente usa um fitbit, esses dados de saúde podem ir parar em repositórios de controle duvidoso. De quem é a propriedade dessa informação? De que forma o paciente pode dar seu consentimento, principalmente no caso de dados indiretos? Como balancear a necessidade de privacidade com a demanda por inovações, por abordagens disruptivas em saúde? Muitos avanços e descobertas clínicas dependem do acesso a esses dados e entraves podem engessar novas descobertas. A solução está em encontrar um balanço que preserve a privacidade do paciente, mas permita de forma segura que esses dados possam beneficiar a saúde pública, pessoal, novos negócios e inovações.
Provavelmente, há de se fazer ajustes de pensamento nesse momento de Big Data e IA. É uma nova velocidade para descobertas em saúde, monitoração e negócios. Os ajustes também têm que acontecer nos domínios médicos, éticos, comerciais entre outros. Mais que ajustes, serão necessárias novas regulações e políticas. Ainda estamos despreparados para tantas mudanças, e talvez o maior desafio seja promover um cuidado de saúde melhor (por exemplo, salvando vidas) como o maior desfecho dessas novas tecnologias.



Sobre os autores
Monica Matsumoto é cientista e professora de Engenharia Biomédica no ITA. Curiosa, ela tem interesse em áreas multidisciplinares e procura conectar pesquisadores em diferentes campos do conhecimento. Monica é formada em engenharia pelo ITA e doutora em ciências pela USP, e trabalhou em diferentes instituições como InCor/HCFMUSP, UPenn e EyeNetra.
Shridhar Jayanthi é Agente de Patentes com registro no escritório de patentes norte-americano (USPTO) e tem doutorado em Engenharia Elétrica pela Universidade de Michigan (EUA) e diploma de Engenheiro de Computação pelo ITA. Atualmente, ele trabalha com empresas de alta tecnologia para facilitar obtenção de patentes e, nas (poucas) horas vagas, é um estudante de problemas na intersecção entre direito, tecnologia e sociedade. Antes disso, Shridhar teve uma vida acadêmica com passagens pela Rice, MIT, Michigan, Pennsylvania e no InCor/USP, e trabalhou com pesquisa em áreas diversas da matemática, computação e biologia sintética.










ID: {{comments.info.id}}
URL: {{comments.info.url}}
Ocorreu um erro ao carregar os comentários.
Por favor, tente novamente mais tarde.
{{comments.total}} Comentário
{{comments.total}} Comentários
Seja o primeiro a comentar
Essa discussão está encerrada
Não é possivel enviar novos comentários.
Essa área é exclusiva para você, assinante, ler e comentar.
Só assinantes do UOL podem comentar
Ainda não é assinante? Assine já.
Se você já é assinante do UOL, faça seu login.
O autor da mensagem, e não o UOL, é o responsável pelo comentário. Reserve um tempo para ler as Regras de Uso para comentários.